E3DGE: Self-Supervised Geometry-Aware Encoder for Style-Based 3D GAN Inversion
CVPR, 2023
Paper
Abstract
StyleGAN has achieved great progress in 2D face reconstruction and semantic editing via image inversion and latent editing. While studies over extending 2D StyleGAN to 3D faces have emerged, a corresponding generic 3D GAN inversion framework is still missing, limiting the applications of 3D face reconstruction and semantic editing. In this paper, we study the challenging problem of 3D GAN inversion where a latent code is predicted given a single face image to faithfully recover its 3D shapes and detailed textures. The problem is ill-posed: innumerable compositions of shape and texture could be rendered to the current image. Furthermore, with the limited capacity of a global latent code, 2D inversion methods cannot preserve faithful shape and texture at the same time when applied to 3D models. To solve this problem, we devise an effective self-training scheme to constrain the learning of inversion. The learning is done efficiently without any real-world 2D-3D training pairs but proxy samples generated from a 3D GAN. In addition, apart from a global latent code that captures the coarse shape and texture information, we augment the generation network with a local branch, where pixel-aligned features are added to faithfully reconstruct face details. We further consider a new pipeline to perform 3D view-consistent editing. Extensive experiments show that our method outperforms state-of-the-art inversion methods in both shape and texture reconstruction quality.
Real-World
Texture/Geometry Inversion Results
Shown texture and shape inversion of given real world identity (CelebA HQ test set). Drag the separator to see the aligned texture and geometry.


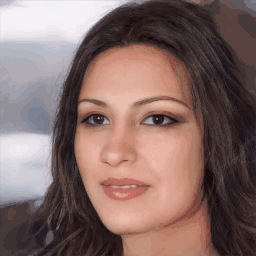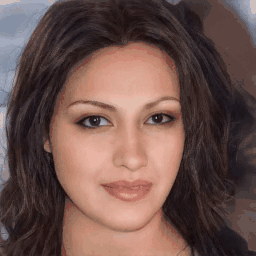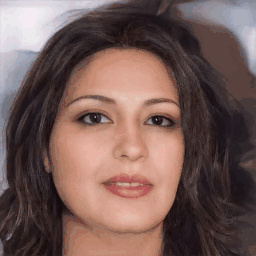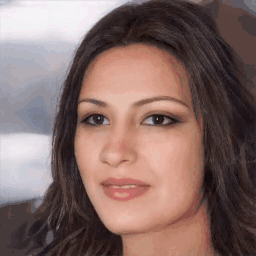



























Geometry-aware
Attribute Editing
Shown editing performance on 4 attributes at different scales, where \(\alpha \) defines the editing scale of vector arithmetics. Drag the separator to see the aligned texture and geometry.




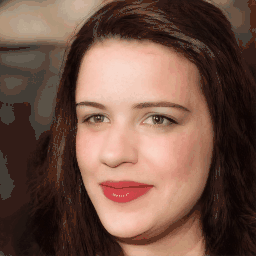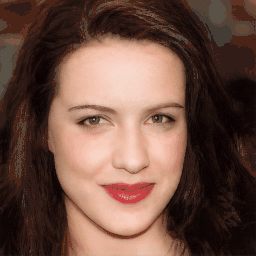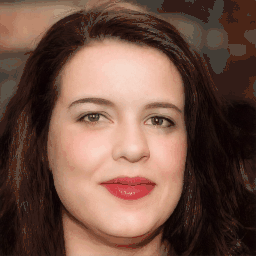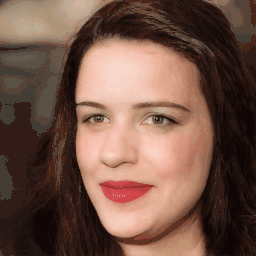




























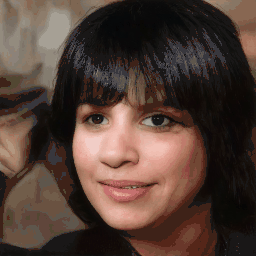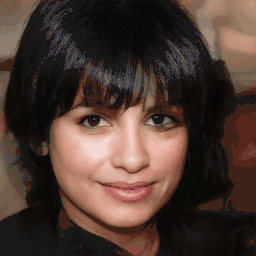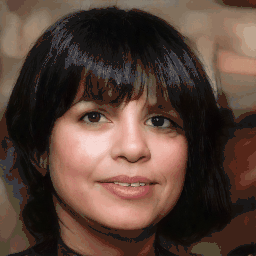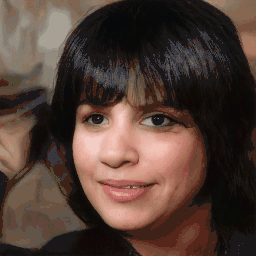

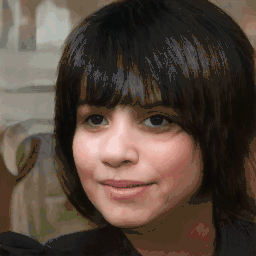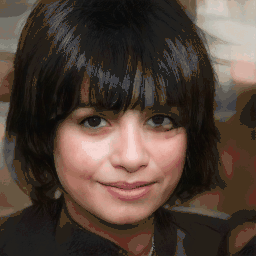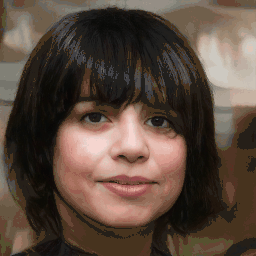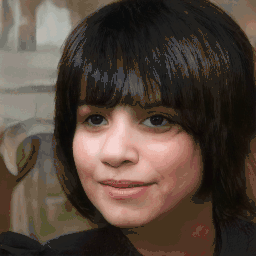
Geometry-Aware
Toonify
Drag the separator to see the aligned texture and geometry of toonified results.











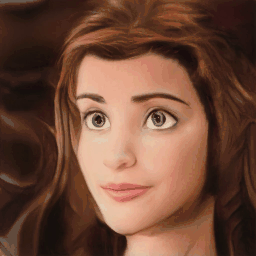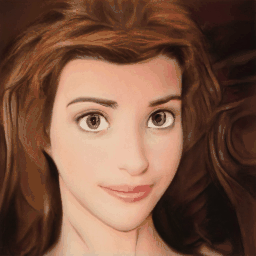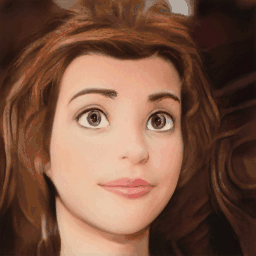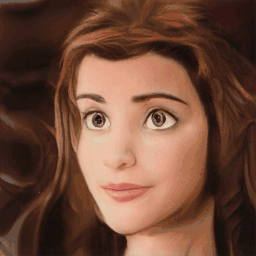



Method Overview
Self-supervised Inversion Learning
for plausible shape inversion
Different compositions of shape and texture could lead to identical 2D
rendered images.
To alleviate such shape-texture ambiguity, we argue that 3D supervision is
indispensible.
In the lack of large-scale high-quality 2D-3D paired samples, we formulate GAN
Inversion as a self-training task, where samples synthesized from
itself are leveraged to boost the reconstruction fidelity in
both 2D and 3D domains.
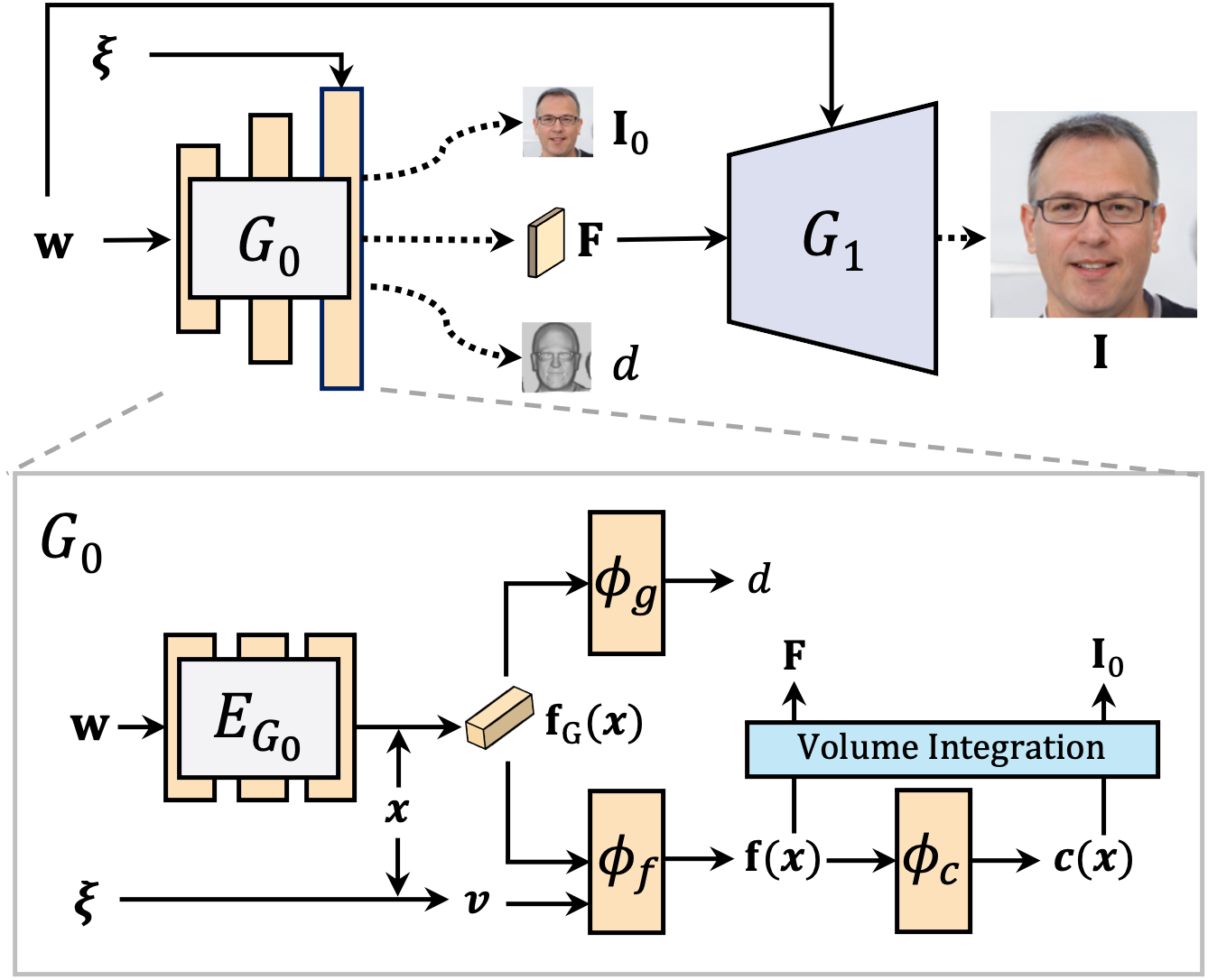
As shown in the figure, we retrofit the generator of a 3D GAN model to provide
us with diverse pseudo training samples.
Given a sampled latent code \(\mathcal{W}\) and a camera pose \( \mathbf{\xi}\),
we sample object SDF to depict the shape and the corresponding face image \(
\mathbf{I} \).
pixel-aligned Features
for High-Fidelity Inversion
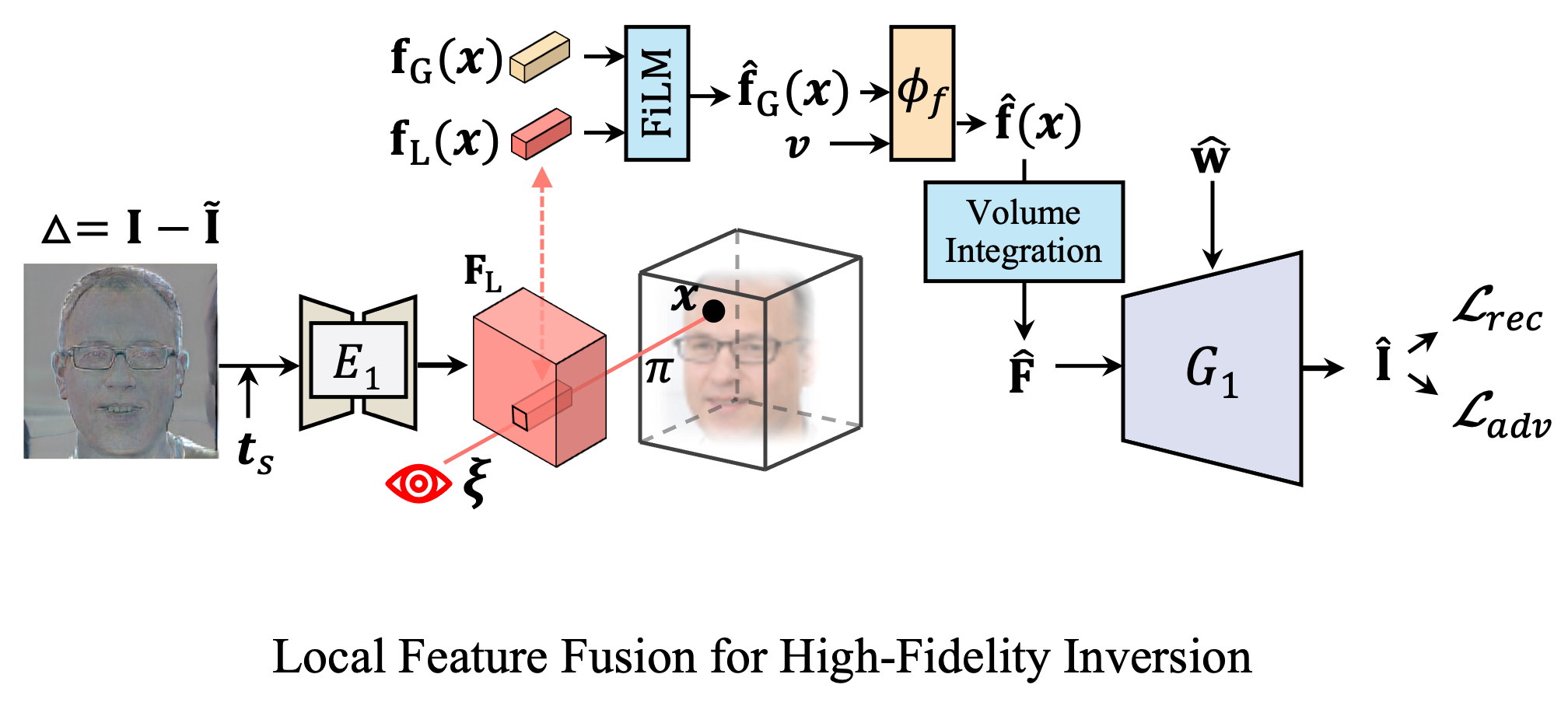
A global latent code fails to capture details for high-fidelity inversion. To address this problem, our novelty here is to leverage local features (pixel-aligned features) to enhance the representation capacity, beyond just the global latent code generated by the inversion encoder. Specifically, in addition to inferring an editable global latent code to represent the overall shape of the face, we further devise an hour-glass model to extract local features over the residuals details that the global latent code fails to capture.
Hybrid Alignment
for High-quality editing
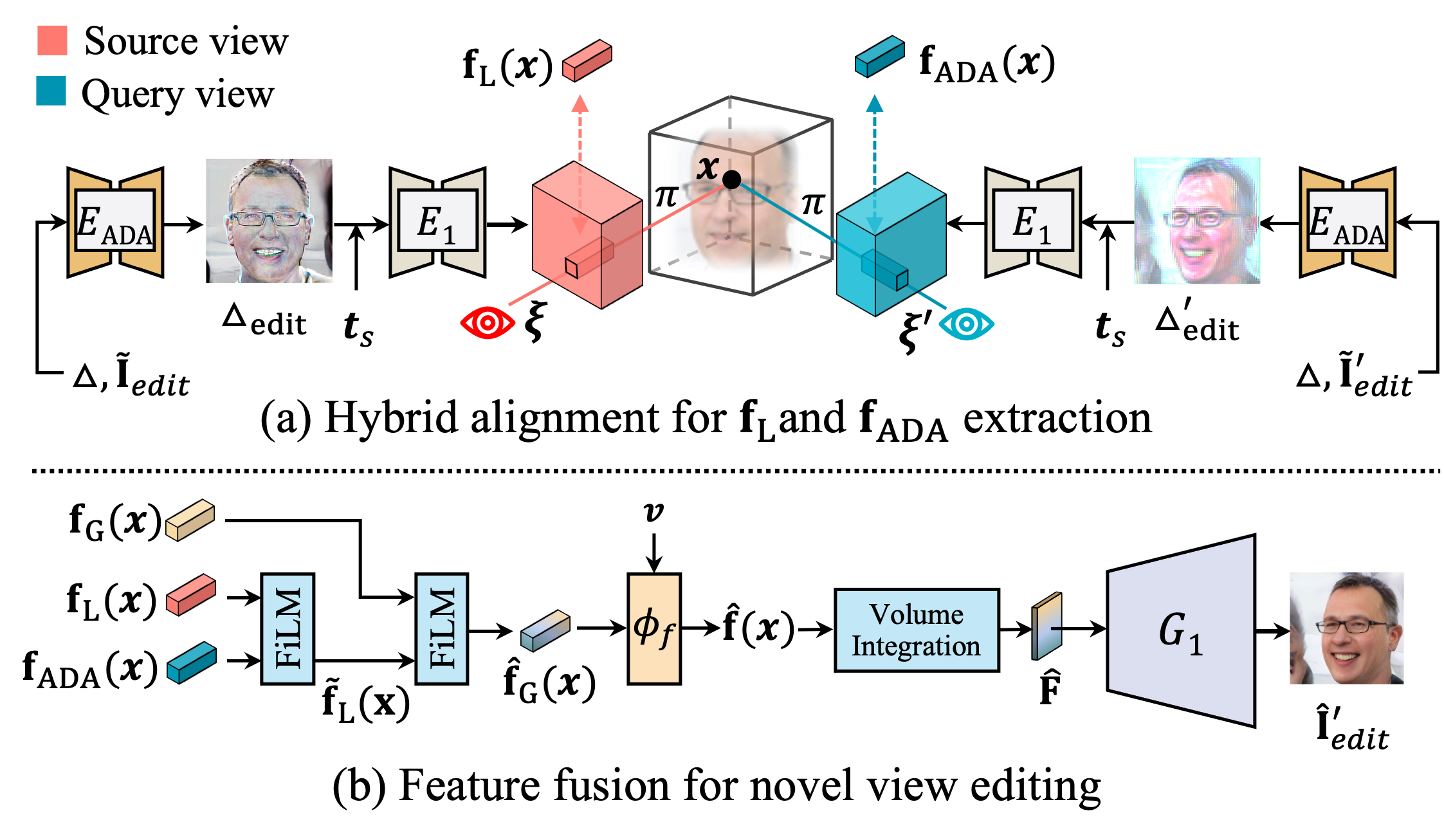
The third component addresses the problem of novel view synthesis, a problem unique to 3D shape editing. Specifically, though we achieve high-fidelity reconstruction through aforementioned designs, the local residual features may not fully align with the scene when being semantically edited. Moreover, the occlusion issue further degrades the fusion performance when rendering from novel views with large pose variations. To address this issue, (a) we propose a 2D-3D hybrid alignment module for high-quality editing. A 2D alignment module and a 3D projection scheme are introduced to jointly align the local features with edited images. (b) The aligned local features are fused with FiLM layer and inpaint occluded local features in novel view synthesis.
Demo Video
Paper
Citation
@article{lan2023e3dge,
title={E3DGE: Self-supervised Geometry-Aware Encoder for Style-based 3D GAN
Inversion},
author={Lan, Yushi and Meng, Xuyi and Yang, Shuai and Loy, Chen Change and Dai, Bo},
booktitle={Computer Vision and Pattern Recognition (CVPR)},
year={2023}
}
Related
Projects
-
Correspondence Distillation from NeRF-based GAN
Y. Lan, C. C. Loy, B. Dai
arXiv preprint [arXiv] [Project Page]
