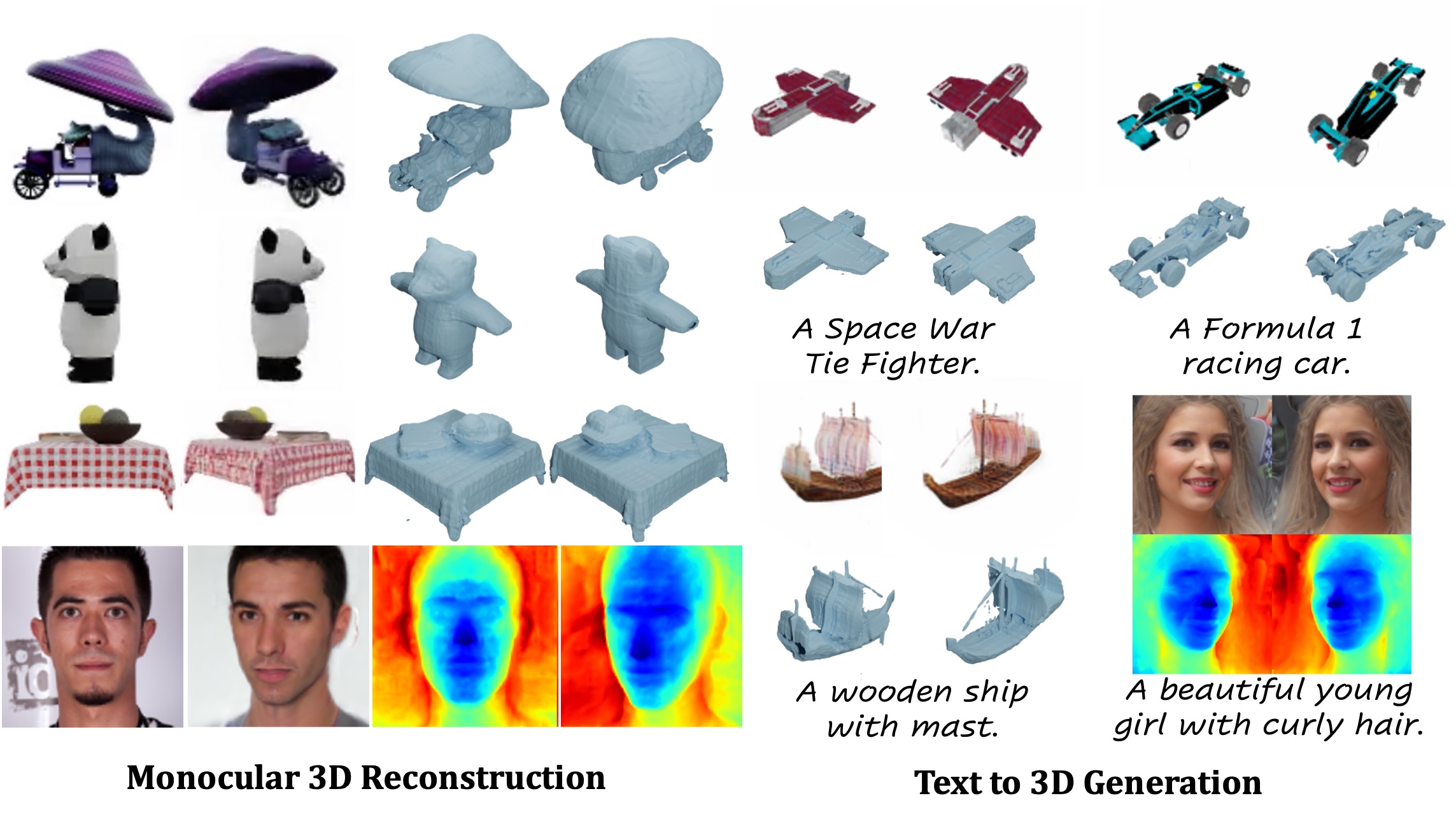
LN3Diff performs efficient 3D diffusion learning over a compact latent space. The resulting model enables both high-quality monocular 3D reconstruction and text-to-3D synthesis.
LN3Diff performs efficient 3D diffusion learning over a compact latent space. The resulting model enables both high-quality monocular 3D reconstruction and text-to-3D synthesis.
The field of neural rendering has witnessed significant progress with advancements in generative models and differentiable rendering techniques. Though 2D diffusion has achieved success, a unified 3D diffusion pipeline remains unsettled. This paper introduces a novel framework called LN3Diff to address this gap and enable fast, high-quality, and generic conditional 3D generation. Our approach harnesses a 3D-aware architecture and variational autoencoder (VAE) to encode the input image into a structured, compact, and 3D latent space. The latent is decoded by a transformer-based decoder into a high-capacity 3D neural field. Through training a diffusion model on this 3D-aware latent space, our method achieves state-of-the-art performance on ShapeNet for 3D generation and demonstrates superior performance in monocular 3D reconstruction and conditional 3D generation across various datasets. Moreover, it surpasses existing 3D diffusion methods in terms of inference speed, requiring no per-instance optimization. Our proposed LN3Diff presents a significant advancement in 3D generative modeling and holds promise for various applications in 3D vision and graphics tasks.
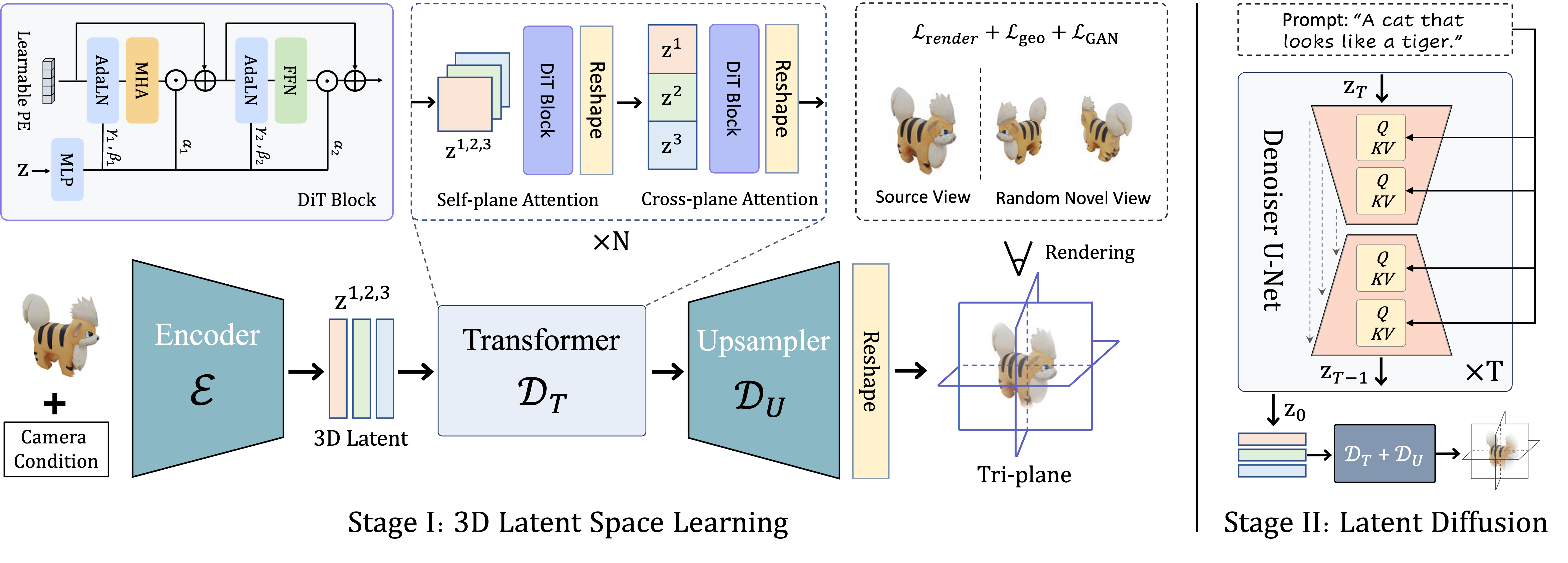
The overall architecture of LN3Diff. We propose to first learn a 3D latent space, where a monocular image is encoded into the KL-regularized latent space. The encoded 3D latent is decoded by a 3D-aware DiT transformer, and up-sampled towards a high-res tri-plane for rendering supervisions. In the second stage, we perform efficient conditional diffusion learning over the compact latent space.
Efficient conditional diffusion training on the 3D latent space.
High-fidelity 3D reconstruction with the proposed 3D-aware VAE.
State-of-the-art performance on the common ShapeNet benchmark.
Our work is inspired by the following work:
Stable Diffusion introduce a general diffusion framework on the VAE latent space.
LRM introduces a large-scale monocular 3D reconstruction model.
@inproceedings{lan2024ln3diff,
title={LN3Diff: Scalable Latent Neural Fields Diffusion for Speedy 3D Generation},
author={Lan, Yushi and Hong, Fangzhou and Yang, Shuai and Zhou, Shangchen and Meng, Xuyi and Dai, Bo and Pan, Xingang and Loy, Chen Change},
year={2024},
booktitle={ECCV},
}