|
I am a postdoctoral researcher at the Visual Geometry Group, University of Oxford, working with Prof. Andrea Vedaldi. I received my Ph.D. from Nanyang Technological University, advised by Prof. Chen Change Loy and Asst. Prof. Xingang Pan at MMLab@NTU. Earlier, I earned my B.Eng in Software Engineering from Yepeida Honors College, BUPT. |

|
|
My interests lie in the intersection of CV, CG, and ML. I am now interested in Spatial AI, Embodied AI, Physical AI, 3D AIGC, and especially World Models. I have worked on Shape Analysis, Inverse Graphics / Neural rendering, and 3D Avatar. |
|
|
Gabrijel Boduljak, Yushi Lan, Christian Rupprecht, Andrea Vedaldi arXiv, 2025 project page / arXiv / code / bibtex VFMF performs stochastic forecasting of future world in VFMs (vision foundation models) latent space. |
|
|
Zeqi Xiao, Yiwei Zhao, Lingxiao Li, Yushi Lan, Ning Yu, Rahul Garg, Roshni Cooper, Mohammad H. Taghavi, Xingang Pan arXiv, 2025 project page Video4Spatial can perform complex visuospatial intelligence reasoning from vidoe alone. |
|
|
Yushi Lan*, Yihang Luo*, Fangzhou Hong, Shangchen Zhou, Honghua Chen, Zhaoyang Lyu, Shuai Yang, Bo Dai, Chen Change Loy, Xingang Pan arXiv, 2025 project page / arXiv / code / bibtex STream3R resolves streaming 3D/4D reconstruction as a sequential registration task with causal attention. |
|
|
Honghua Chen, Yushi Lan, Yongwei Chen, Xingang Pan SIGGRAPH Asia, 2025 project page / arXiv / code / bibtex ArtiLatent generates articulated 3D object. |
|
|
Zeqi Xiao, Yushi Lan, Yifan Zhou, Wenqi Ouyang, Shuai Yang, Yanhong Zeng, Xingang Pan NeurIPS, 2025 project page / arXiv / code / demo / bibtex WORLDMEM enables long-term memory for video world models. |

|
Songlin Yang, Yushi Lan, Honghua Chen, Xingang Pan ICCV, 2025 project page / arXiv / Code / bibtex GaussianAnything generates high-quality and editable surfel Gaussians through a cascaded 3D diffusion pipeline, given single-view images or texts as the conditions. |
|
|
Yushi Lan, Shangchen Zhou, Zhaoyang Lyu, Fangzhou Hong, Shuai Yang, Bo Dai, Xingang Pan, Chen Change Loy ICLR, 2025 project page / arXiv / Code / Demo / bibtex GaussianAnything generates high-quality and editable surfel Gaussians through a cascaded 3D diffusion pipeline, given single-view images or texts as the conditions. |
|
|
Yongwei Chen, Yushi Lan, Shangchen Zhou, Tengfei Wang, Xingang Pan CVPR, 2025 project page / pdf / Code / Video / bibtex SAR3D generates and understands 3D object in a scale-level autoregressive way. |

|
Yihang Luo, Shangchen Zhou, Yushi Lan, Xingang Pan, Chen Change Loy CVPR, 2025 project page / arXiv / Code / Video / bibtex 3DEnhancer enhances low-quality 3D assets through multi-view diffusion priors. |

|
Zhaoxi Chen, Jiaxiang Tang, Yuhao Dong, Ziang Cao, Fangzhou Hong, Yushi Lan, Tengfei Wang, Haozhe Xie, Tong Wu, Shunsuke Saito, Liang Pan, Dahua Lin, Ziwei Liu, CVPR, 2025 project page / arXiv / Code 3DTopia-XL scales high-quality 3D asset generation using Diffusion Transformer (DiT) built upon an expressive and efficient 3D representation, PrimX. |
|
|
Yushi Lan, Fangzhou Hong, Shuai Yang, Shangchen Zhou, Xuyi Meng, Bo Dai, Xingang Pan, Chen Change Loy ECCV, 2024 project page / TPAMI / arXiv / Code / bibtex LN3Diff is a native 3D diffusion model that creates high-quality 3D object mesh from image or text within 8 seconds. |
|
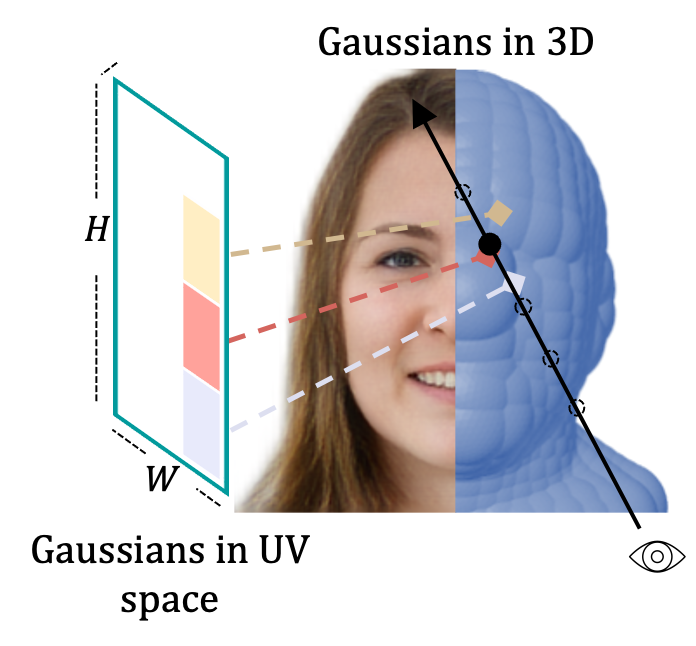
Yushi Lan, Feitong Tan, Di Qiu, Qiangeng Xu Kyle Genova Zeng Huang, Sean Fanello, Rohit Pandey, Thomas Funkhouser, Chen Change Loy, Yinda Zhang ECCV, 2024 project page / arXiv / bibtex Gaussian3Diff adopts 3D Gaussians defined in UV space as the underlying 3D representation, which intrinsically support high-quality novel view synthesis, 3DMM-based animation and 3D diffusion for unconditional generation. |
|
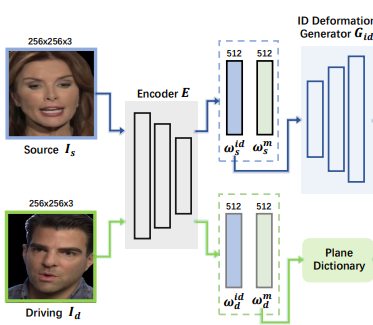
Songlin Yang, Wei Wang, Yushi Lan, Xiangyu Fan, Bo Peng, Lei Yang, Jing Dong AAAI, 2024 project page / arXiv We propose a novel face reenactment framework, which adopts tri-planes as fundamental NeRF representation and decomposes face tri-planes into three components: canonical tri-planes, identity deformations, and motion. |

|
Junzhe Zhang*, Yushi Lan*, Shuai Yang, Fangzhou Hong, Quan Wang, Chai Kiat Yeo, Ziwei Liu, Chen Change Loy ICCV, 2023 project page / arXiv / Code / bibtex We propose DeformToon3D, an 3D toonification methods that achieves high-quality geometry and texture stylization under given styles. |

|
Yushi Lan, Xuyi Meng, Shuai Yang, Chen Change Loy, Bo Dai CVPR, 2023; IJCV, 2025 project page / IJCV / arXiv / video / Code / bibtex We propose E3DGE, an encoder-based 3D GAN inversion framework that yields high-quality shape and texture reconstruction. |

|
Fangzhou Hong, Zhaoxi Chen, Yushi Lan, Liang Pan, Ziwei Liu ICLR, 2023, Spotlight project page / arXiv / video / Code / bibtex EVA3D is a high-quality unconditional 3D human generative model that only requires 2D image collections for training. |
|
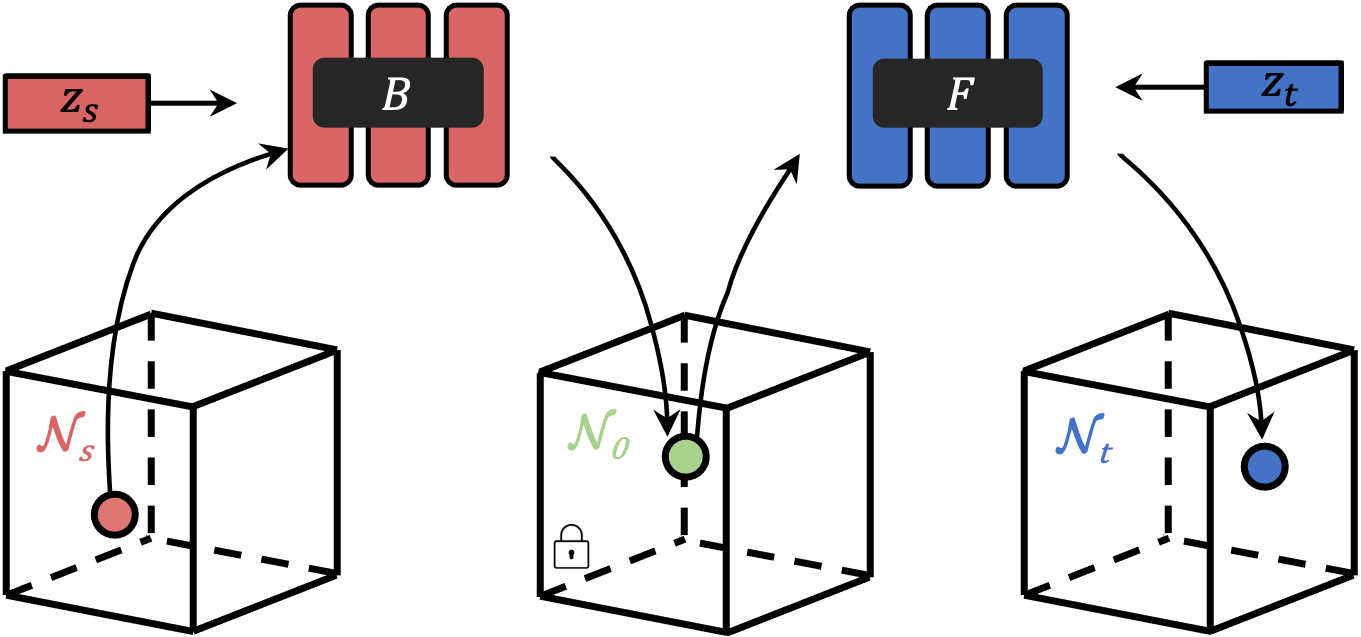
Yushi Lan, Chen Change Loy, Bo Dai IJCV, 2022 project page / arXiv / Springer / bibtex We study dense correspondence, which plays a key role in 3D scene understanding but has been ignored in NeRF research. DDF presents a novel way to distill dense NeRF correspondence from pre-trained NeRF GAN unsupervisedly. |
|
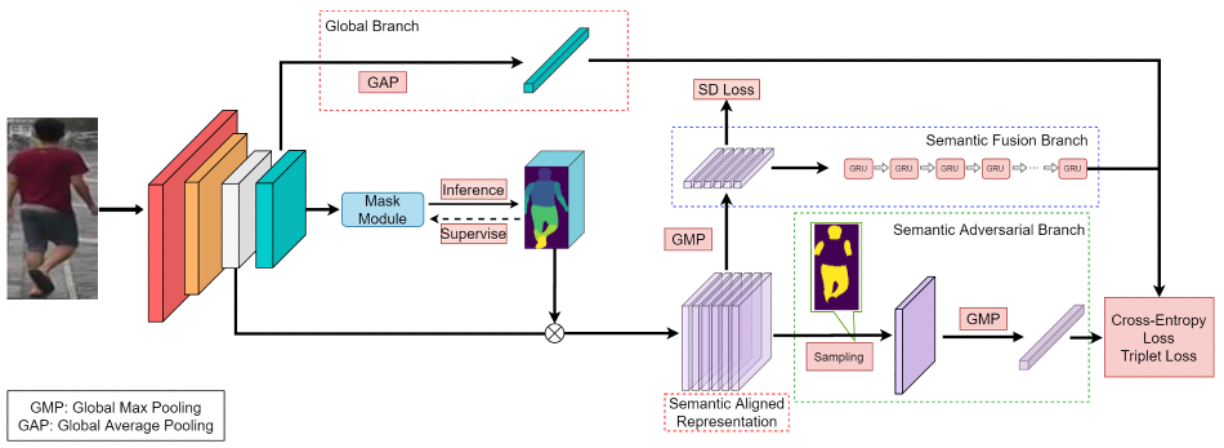
Yushi Lan*, Yuan Liu*, Xinchi Zhou, Maoqing Tian, Xuesen Zhang, Shuai Yi, Hongsheng Li, BMVC, 2020 arXiv / Code We propose MagnifierNet, a triple-branch network which accurately mines details from whole to parts in person re-identification (ReID). |
|
Design and source code from Jon Barron's website |